Minesweeper solver using NN
Alisher Tortay, Oleg Yurchecnko
KAIST, 2016
Abstract
MineSweeper is a popular puzzle game developed by Microsoft. For the past two decades a number of approaches to solve the game were presented. Most of them are based on estimating the probability of a covered tile to be a mine. Recent research from Stanford University proposed an interesting attempt to apply modern reinforcement learning techniques to this problem. In this paper we present another approach for solving MineSweeper game using neural network classifier. We were able to obtain results comparable to those of the state of the art algorithms.
You can find source code with original paper and sample video on github and youtube, respectively.
Why Minesweeper?
Playing this game requires use of logic and awareness of relations between neighboring fields. It is a game of imperfect information and checking the state of board for solutions is NP complete problem. Therefore, playing minesweeper with neural networks is challenging and interesting research topic in Artificial Intelligence. Our goal in this project was to implement Neural Network based agent that can play Minesweeper.
Literature Review
Recent development of machine learning caused a revival in interest in using machine learning and reinforcement learning techniques in the computer game industry. During the past few years number of different attempts have been made to solve wide range of games. State of the art algorithms for RL include Q-learning, policy gradient, and number of other approaches. For instance, in 2013 DeepMind in their paper presented a deep convolutional neural network using which they achieved huge performance in playing Atari 2600 games. Similar networks and techniques were used for other games, such as Flappy Bird, Out Run, etc.
As for MineSweeper solver, wide range of methods had been applied starting from analytical solutions, genetic algorithms to Q-learning method. The first attempts to solve MineSweeper game were developed in 1990’s. Such that, in 1997, A. Adamatzky showed how to mark all mines populated on n*n board using two-dimensional cellular automaton in (n)time. The state of art method for solving MineSweeper game is limited search with probability estimates strategy proposed by K. Pedersen in 2004. The solver based on this method achieved 92,5% win rate on the beginner board, and 25% on expert level.
There also have been few attempts to use machine to play the game. In 2015 students from Stanford University applied supervised learning using SVM classifier and linear regression model, and Q-learning algorithm based on Q-tables. However, performance of those approaches dramatically decreases as the size of the board increases. For instance, the win-rate for Q-learning algorithm reaches 70% for 44 board with 3 mines, but falls to the level of around 5% for 55 boards with 5 mines (the density of mines is nearly 20% on those boards). Meanwhile, other algorithms have even lower win rate.
Methods and Approach
Due to the lack of availability of Minesweeper frameworks capable of implementing an automated player, we wrote our own version of minesweeper game. In our game there is no mine at position (0,0). Interface works as follows: we open a square using open(pos) function and mark a tile using mark(pos) function. This functions returns state in the form of array(1,n*m) and whether game is finished. From the game we also can obtain true positions of all mines; we will use this information to train our agents.
Supervised Learning Agent (SLA)
We used supervised learning model to implement this agent. We designed three feed-forward neural networks with different sizes. Input is subboard of size 5x5. A tile has 12 possible values: uncovered, flag, out-of-board, and integers from 0 to 8. Each tile in this subboard is represented using one hot encoding. Output is one number between 0 and 1: probability that central tile of the 5x5 subboard does not contain a mine. We trained our networks with with following values: 0 if central tile of 5x5 input contains a mine and 1 otherwise. We define perimeter as a set of tiles that have at least one uncovered or marked neighbor.
Supervised Learning Algorithm
- begin by probing upper-left corner
- while not game over do
- foreach tile in the perimeter
- predict probability
- if probability < 0.1
- mark the tile as mine
- else if probability > 0.1
- unmark the tile
- end if
- end foreach
- foreach tile in the perimeter
- predict probability
- save this training sample into experience buffer
- end foreach
- open a tile with maximal probability
- end while
- train network using random sample from experience buffer
As you can see from the algorithm we save training samples into experience buffer and trained our networks by randomly choosing samples from the buffer. Moreover, we predict probabilities for each tile of perimeter twice. In first round we put or remove flags. In second round we use information from uncovered tiles as well as flag information form first round. After predicting probabilities from second round we open the tile with highest probability (of being safe).
Input size is 25 * 12 = 300. We designed three feed-forward neural networks for supervised learning model.
- Small: Three hidden layers of sizes 300, 256, and 128, respectively
- Large-A: Four hidden layers of size 300, 256, 128, and 64, respectively
- Large-B: Four hidden layers of size 300, 256, 256, and 128, respectively
It is important to point out that this model scales perfectly on a board of any size because we always train the same network. That is, training and prediction time is same for all boards.
Modified Supervised Learning Agent (MSLA)
In some cases it is impossible to say if a given tile contains a mine. Therefore, in the model above we train our network with values that are sometimes infeasible. For example, suppose we have two covered tiles with same “true” probability of being safe. Ideally in this case our model should return 0.5 probability for each. However, we always train our model only with 1 or 0. To solve this problem we implemented modified version of supervised learning model. In this modification instead of training with 1 and 0, we use probabilities from other solver. In other words we approximate another solver using neural networks. This approach is useful when computation time of original solver is too long. In this model we used very simple solver based on additive properties of Minesweeper game.
Results and Analysis
Before testing we trained each of three supervised learning networks on 16x16 board with different number of mines.
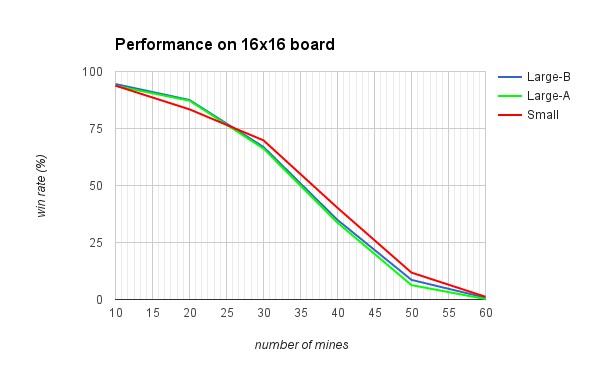
We tested all three SLA Neural Networks on 16x16 boards with different mine numbers . From the line chart above we can see that neural networks with 4 hidden layers (Large-A and Large-B) perform better that network with 3 hidden layers (Small) on boards with low density of mines. However, on boards with high density of mines Small performs better than both Large-A and Large-B. In general, Large-B and Large-A have similar win rates over all mine densities.
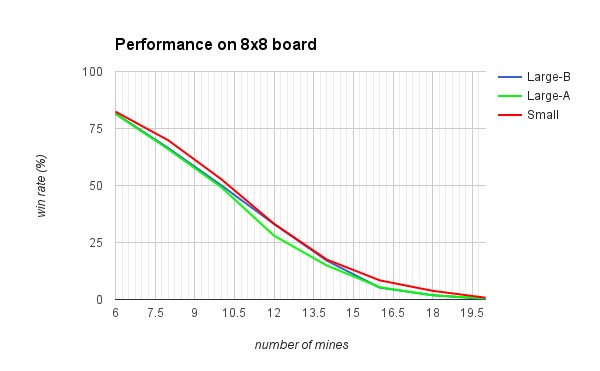
We also tested all three SLA Neural Networks on 8x8 boards with different mine numbers. Small has the highest win rate and Large-A has the lowest win rate over all mine densities. In general, Large-B perform similar to Large-A, however, on boards with moderate density it matches with Small.
These results were quite surprising; we expected that NNs with more layers will perform better since they have higher complexity. However, more layers take more time to train. That could be a reason of their poor performance. It is also important how NNs are trained. If NN is trained only on boards with low density of mines, it will have very low win rate on boards with high density of mines.
From the table below we can see that both MSLA and solver for MSLA have low win rate compared to our SLA networks. However, it is worth noticing that MSLA approximates its solver quite well. Therefore, solver is the bottleneck for MSLA. This problem could be solved using a better solver to approximate.
| Board size and # of mines | Density | Small | Large-A | Large-B | MSLA | Solver for MSLA | Pedersen |
|---|---|---|---|---|---|---|---|
| 8x8, 8 | 12.5% | 69.8% | 65.9% | 66.4% | 30.7% | 33.5% | 92.5% |
| 8x8, 10 | 15.6% | 52.8% | 49.3% | 50.1% | 11% | 15.3% | - |
| 10x10, 10 | 10% | - | - | - | 39.2% | 40% | - |
| 16x16, 20 | 7.8% | 83.4% | 87.2% | 87.5% | 40.4% | 47% | - |
| 16x16, 40 | 15.6% | 40.2% | 33.7% | 34.9% | 0% | 0% | 67.7% |
Additionally, the table compares our models to limited search with probability estimates strategy (Pedersen) for two boards. In both cases limited search with probability estimates strategy outperforms our models. However, our models, once trained, are faster than the limited search. Overall, proposed models show significant improvement compare to previous attempts of using neural networks for MineSweeper agent.
We also implemented convenient interface for the game to visualize the process of ‘thinking’ or estimating probabilities. In our game implementation we used different colors that would represent predicted probabilities. In figure above green color represents “safeness” and purple color represents mines. Using this representation we are able to understand how our model “thinks”. We can see that in certain tiles our agent is more confident than in others. You can watch sample video on youtube.

Further Research/Work
Since our MSLA approach is based on the approximation of ‘safe’ probability, one obvious way to improve success rate is to use better solver. For instance, we propose to use the limited search with probability estimates strategy (K. Pedersen) as a true oracle. Also, this approach will give us a better insight into situations in which it is potentially impossible to be certain about the true probability of the safe choice. This will prevent the cost function from significant fluctuations and possibly improve and speed up learning process. In addition, we believe that it would be beneficial to try to approximate other probabilistic methods, such as SCP, rejection method (for consistent belief state estimation), MCMC, etc.
Find out more by visiting the project on GitHub.